Определение на формула за F-тест
Формулата на F-тест се използва, за да се извърши статистически тест, който помага на лицето, което провежда теста, да установи дали двата набора от популации, които имат нормалното разпределение на точките от данни от тях, имат същото стандартно отклонение или не.
F-тест е всеки тест, който използва F-разпределение. F стойност е стойност на F разпределението. Различни статистически тестове генерират F стойност. Стойността може да се използва, за да се определи дали тестът е статистически значим. За да се сравнят две дисперсии, трябва да се изчисли съотношението на двете дисперсии, което е както при:
F Стойност = по-голяма дисперсия на пробата / по-малка дисперсия на пробата = σ 1 2 / σ 2 2
Докато F-тестваме в Excel, трябва да поставим в рамка нулевите и алтернативните хипотези. След това трябва да определим нивото на значимост, при което трябва да се проведе тестът. Впоследствие трябва да открием степента на свобода както на числителя, така и на знаменателя. Това ще помогне да се определи стойността на таблицата F. След това стойността F, видяна в таблицата, се сравнява с изчислената стойност F, за да се определи дали да се отхвърли нулевата хипотеза или не.
Изчисление стъпка по стъпка на F-тест
По-долу са стъпките, при които формулата F-Test се използва за нулевата хипотеза, че дисперсиите на две популации са равни:
- Стъпка 1: Първо, формулирайте нулевата и алтернативната хипотеза. Нулевата хипотеза предполага, че дисперсиите са равни. H 0 : σ 1 2 = σ 2 2 . Алтернативната хипотеза гласи, че отклоненията са неравномерни. H 1 : σ 1 2 ≠ σ 2 2 . Тук σ 1 2 и σ 2 2 са символите за отклонения.
- Стъпка 2: Изчислете тестовата статистика (F разпределение). т.е. = σ 1 2 / σ 2 2, където σ 1 2 се приема за по-голяма дисперсия на пробата, а σ 2 2 е по-малката дисперсия на пробата
- Стъпка 3: Изчислете степента на свобода. Степен на свобода (df 1 ) = n 1 - 1 и Степен на свобода (df 2 ) = n 2 - 1, където n 1 и n 2 са размерите на извадката
- Стъпка 4: Погледнете стойността F в таблицата F. За двустранни тестове разделете алфата на 2 за намиране на правилната критична стойност. Така се намира стойността F, като се разглеждат степента на свобода в числителя и знаменателя в таблицата F. Df 1 се чете в горния ред. Df 2 се чете в първата колона.


Забележка: Има различни F таблици за различни нива на значимост. По-горе е F таблицата за алфа = .050.
- Стъпка 5: Сравнете статистиката F, получена в стъпка 2 с критичната стойност, получена в стъпка 4. Ако статистиката F е по-голяма от критичната стойност на необходимото ниво на значимост, ние отхвърляме нулевата хипотеза. Ако статистиката F, получена в стъпка 2, е по-малка от критичната стойност на необходимото ниво на значимост, не можем да отхвърлим нулевата хипотеза.
Примери
Пример # 1
Един статистик извършва F-тест. Той получи F статистиката като 2,38. Степените на свобода, получени от него, бяха 8 и 3. Разберете стойността F от таблицата F и определете дали можем да отхвърлим нулевата хипотеза при 5% ниво на значимост (тест с една опашка).
Решение:
Трябва да търсим 8 и 3 степени на свобода във F таблицата. Критичната стойност на F, получена от таблицата, е 8.845 . Тъй като статистиката F (2,38) е по-малка от стойността на таблицата F (8,845), не можем да отхвърлим нулевата хипотеза.
Пример # 2
Застрахователна компания продава здравни застраховки и полици за автомобилно застраховане. За тези политики клиентите плащат премии. Главният изпълнителен директор на застрахователната компания се пита дали премиите, платени от който и да е от застрахователните сегменти (здравно осигуряване и автомобилно застраховане), са по-променливи в сравнение с друг. Той намира следните данни за платени премии:

Проведете двустранен F-тест с ниво на значимост 10%.
Решение:
- Стъпка 1: Нулева хипотеза H 0 : σ 1 2 = σ 2 2
Алтернативна хипотеза H a : σ 1 2 ≠ σ 2 2
- Стъпка 2: F статистика = F Стойност = σ 1 2 / σ 2 2 = 200/50 = 4
- Стъпка 3: df 1 = n 1 - 1 = 11-1 = 10
df 2 = n 2 - 1 = 51-1 = 50
- Стъпка 4: Тъй като това е двустранен тест, алфа ниво = 0,10 / 2 = 0,050. Стойността F от таблицата F със степени на свобода като 10 и 50 е 2.026.
- Стъпка 5: Тъй като F статистиката (4) е повече от получената стойност на таблицата (2.026), ние отхвърляме нулевата хипотеза.
Пример # 3
Банката има централен офис в Делхи и клон в Мумбай. В единия офис има дълги клиентски опашки, докато в другия офис опашките на клиентите са кратки. Операционният мениджър на банката се пита дали клиентите в един клон са по-променливи от броя на клиентите в друг клон. Изследване на клиенти се извършва от него.
Дисперсията на клиентите от централния офис в Делхи е 31, а тази за клона в Мумбай е 20. Размерът на извадката за централния офис в Делхи е 11, а този за клона в Мумбай е 21. Проведете двустранен F-тест с ниво със значимост 10%.
Решение:
- Стъпка 1: Нулева хипотеза H 0 : σ 1 2 = σ 2 2
Алтернативна хипотеза H a : σ 1 2 ≠ σ 2 2
- Стъпка 2: F статистика = F Стойност = σ 1 2 / σ 2 2 = 31/20 = 1,55
- Стъпка 3: df 1 = n 1 - 1 = 11-1 = 10
df 2 = n 2 - 1 = 21-1 = 20
- Стъпка 4: Тъй като това е двустранен тест, алфа ниво = 0,10 / 2 = 0,05. Стойността F от таблицата F със степени на свобода като 10 и 20 е 2,384.
- Стъпка 5: Тъй като F статистиката (1.55) е по-малка от получената стойност на таблицата (2.348), не можем да отхвърлим нулевата хипотеза.
Уместност и употреба
Формулата F-Test може да се използва в голямо разнообразие от настройки. F-тест се използва за тестване на хипотезата, че вариациите на две популации са равни. На второ място, той се използва за тестване на хипотезата, че средствата на дадени популации, които обикновено са разпределени, имащи същото стандартно отклонение, са равни. На трето място, той се използва за тестване на хипотезата, че предложеният регресионен модел отговаря добре на данните.
Формула за F-тест в Excel (с шаблон на Excel)
Работниците в дадена организация получават дневни заплати. Главният изпълнителен директор на организацията е загрижен за променливостта на заплатите между мъжете и жените в организацията. По-долу са данните, взети от извадка от мъже и жени.

Проведете еднократен F тест при ниво на значимост 5%.
Решение:
- Стъпка 1: H 0 : σ 1 2 = σ 2 2 , H 1 : σ 1 2 ≠ σ 2 2
- Стъпка 2: Щракнете върху раздела с данни> Анализ на данни в Excel.

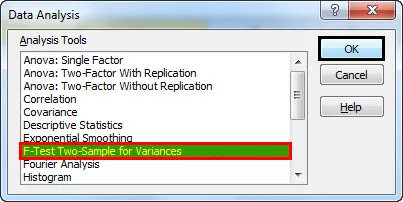
- Стъпка 3: Ще се появи посоченият по-долу прозорец. Изберете F-Test Two-Sample for Variances и след това щракнете върху OK.
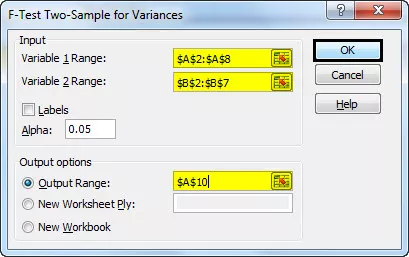
- Стъпка 4: Щракнете върху полето с променлива 1 и изберете диапазона A2: A8. Щракнете върху полето с променлива 2 и изберете диапазона B2: B7. Щракнете върху A10 в изходния диапазон. Изберете 0,05 като алфа, тъй като нивото на значимост е 5%. След това щракнете върху OK.
Стойностите за F статистика и F таблична стойност ще бъдат показани заедно с други данни.
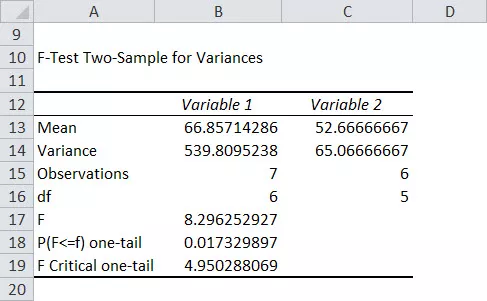
- Стъпка 4: От горната таблица можем да видим F статистика (8.296) е по-голяма от F критична едноопашка (4.95), така че ще отхвърлим нулевата хипотеза.
Забележка 1: Дисперсията на променлива 1 трябва да бъде по-висока от дисперсията на променлива 2. В противен случай изчисленията, направени от Excel, ще бъдат погрешни. Ако не, тогава разменете данните.
Забележка 2: Ако бутонът за анализ на данни не е наличен в Excel, отидете на Файл> Опции. Под Добавки изберете Анализ ToolPak и кликнете върху бутона Go. Проверете пакета с инструменти за анализ и кликнете върху OK.
Забележка 3: В Excel има формула за изчисляване на стойността на таблицата F. Синтаксисът му е:









