Формула за изчисляване на Т разпределението на ученика
Формулата за изчисляване на Т разпределението (което е известно и като Т разпределение на Student) е показана като Изваждане на средната стойност на популацията (средната стойност на втората проба) от средната стойност на пробата (средната стойност на първата проба), което е (x̄ - μ), което след това разделено на стандартното отклонение на средните стойности, което първоначално се разделя на квадратния корен от n, който е броят единици в тази извадка (s ÷ √ (n)).
Разпределението Т е вид разпределение, което изглежда почти като нормалната крива на разпределение или кривата на камбаната, но с малко по-дебела и по-къса опашка. Когато размерът на извадката е малък, тогава това разпределение ще се използва вместо нормалното разпределение.
t = (x̄ - μ) / (s / √n)
Където,
- x̄ е средната стойност на пробата
- μ е средната популация
- s е стандартното отклонение
- n е размерът на дадената проба
Изчисляване на Т разпределението
Изчисляването на t разпределението на ученика е съвсем просто, но да, стойностите са задължителни. Например, човек се нуждае от средното за популацията, което е за Вселената, което не е нищо друго освен средната стойност за популацията, докато средното за пробата е необходимо, за да се провери автентичността на популацията, означава ли твърдението, твърдяно въз основа на популацията, наистина е вярно и проба, ако някоя взета ще представлява същото твърдение. Така че, формулата на t разпределение тук изважда средната стойност на извадката от средната популация и след това я разделя на стандартно отклонение и умножава на квадратния корен от размера на извадката, за да стандартизира стойността.
Тъй като обаче няма диапазон за изчисляване на t разпределението, стойността може да стане странна и няма да можем да изчислим вероятността, тъй като разпределението на t на ученика има ограничения за достигане до стойност и следователно е полезно само за по-малък размер на извадката . Също така, за да се изчисли вероятността след достигане на резултат, трябва да се намери стойността на тази от таблицата за разпределение на t на ученика.
Примери
Пример # 1
Помислете за следните променливи, които са ви дадени:
- Средно население = 310
- Стандартно отклонение = 50
- Размер на пробата = 16
- Средно за пробата = 290
Изчислете стойността на t-разпределението.
Решение:
Използвайте следните данни за изчисляване на Т разпределението.

И така, изчисляването на Т разпределението може да се направи, както следва -
Тук са дадени всички стойности. Просто трябва да включим ценностите.
Можем да използваме формулата за разпределение на t

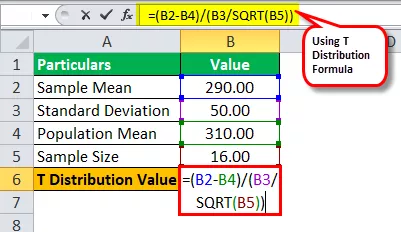
Стойност на t = (290 - 310) / (50 / √16)

T Стойност = -1.60
Пример # 2
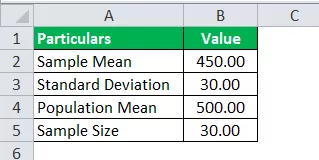
Компанията SRH твърди, че нейните служители на ниво анализатори печелят средно 500 долара на час. Избира се извадка от 30 служители на ниво анализатор, а средната им печалба на час е била $ 450, с примерно отклонение от $ 30. И ако приемем, че твърдението им е вярно, изчислете стойността на t-разпределението, която ще се използва за намиране на вероятността за t-разпределение.
Решение:
Използвайте следните данни за изчисляване на Т разпределението.
И така, изчисляването на Т разпределението може да се направи, както следва -
Тук са дадени всички стойности; просто трябва да включим ценностите.
Можем да използваме формулата за разпределение на t


Стойност на t = (450 - 500) / (30 / √30)

T Стойност = -9.13
Следователно стойността за t резултат е -9,13
Пример # 3
Универсалният съвет на колежа е провел тест за ниво на интелигентност на 50 произволно избрани професори. И резултатът, който откриха от това, беше средният резултат за ниво на IQ беше 120 с дисперсия 121. Да приемем, че резултатът t е 2.407. Какво означава популацията за този тест, което би оправдало стойността на t резултат като 2.407?
Решение:
Използвайте следните данни за изчисляване на Т разпределението.

Тук всички стойности са дадени заедно с t стойност; трябва да изчислим средната стойност на популацията вместо стойността t този път.
Отново ще използваме наличните данни и ще изчислим средните стойности на популацията, като вмъкнем стойностите, дадени във формулата по-долу.
Средното за извадката е 120, средното за популацията е неизвестно, стандартното отклонение на извадката ще бъде квадратен корен от дисперсията, който би бил 11, а размерът на извадката е 50.
И така, изчисляването на средната стойност на популацията (μ) може да се направи, както следва -
Можем да използваме формулата за разпределение на t.


Стойност на t = (120 - μ) / (11 / √50)
2.407 = (120 - μ) / (11 / √50)
-μ = -2.407 * (11 / √50) -120
Средното население (μ) ще бъде -

μ = 116,26
Следователно стойността за средното население ще бъде 116,26
Уместност и употреба
Разпределението на Т (и свързаните с тях t стойности) се използва при тестване на хипотези, когато трябва да се разбере дали трябва да се отхвърли или приеме нулевата хипотеза.

В горната графика централният регион ще бъде зоната на приемане, а опашната област ще бъде регионът на отхвърляне. В тази графика, която е двустранен тест, синьото засенчено ще бъде областта на отхвърляне. Областта в областта на опашката може да бъде описана или с t-резултатите, или с z-резултатите. Вземете пример; изображението вляво ще изобрази площ в опашките от пет процента (което е 2,5% от двете страни). Z-резултатът трябва да бъде 1,96 (като се взема стойността от z-таблицата), което трябва да представлява тези 1,96 стандартни отклонения от средната стойност или средната стойност. Нулевата хипотеза може да бъде отхвърлена, ако стойността на z оценката е по-малка от стойността на -1,96 или стойността на z оценката е по-голяма от 1,96.
По принцип това разпределение се използва, както е описано по-рано, когато човек има по-малък размер на извадката (най-вече под 30) или ако не знае каква е дисперсията на популацията или стандартното отклонение на популацията. От практическа гледна точка (това е в реалния свят), това би било винаги винаги така. Ако размерът на предоставената извадка е достатъчно голям, тогава 2-те разпределения ще бъдат практически сходни.





